Achieving fast upserts for Apache Druid

One of Singular’s core offerings is unifying marketing data. To achieve that we manage a massive pipeline that pushes data from dispersed sources into a single database which is our source of truth and drives all of our analytical capabilities. Our database of choice is Apache Druid and this blog post talks about the challenges in upserting data into Druid in a way that maintains correctness, and query and ingestion speeds.
When we just started a simple MySQL RDS instance was enough to serve all our customers’ reporting needs. As the number of customers, connectors, and historical data grew we found ourselves outgrowing MySQL and have chosen Druid as the new database to hold our analytics data.
Our choice has proved itself and we’ve been using Druid happily for a couple of years now. That is not to say everything was always smooth, as we grew we started having pains with the time it took us to ingest data into Druid. To understand the challenge we were facing we first need to briefly talk about Druid’s data hierarchy and Singular’s data schemes.
Druid’s data hierarchy
Understanding Druid’s data hierarchy is fundamental to understanding our challenges and our thought process. Druid has 3 data hierarchies:
- The topmost unit of data in Druid is called a data source, this is the thing you can actually name and query. There are many types of data sources but for the purpose of this post, we will focus on tables.
- Each table is divided into time chunks (or intervals), which allow Druid to quickly filter queries to specific times. Time-chunks can be divided into varying granularities such as a month, week, day, hour, and so on.
- Druid’s smallest unit of data and processing are segment files and each time-chunk may contain multiple of those. Segment files are columnar storage units that utilize reverse dictionaries, bitmaps, and compression to provide quick queries and filtration.
The service responsible for running queries on Druid is the Broker. For each query, the Broker would consult published metadata to find the segment files matching the queried Datasource and interval. It would then utilize another group of servers called Historicals, each Historical has a set of segment files loaded into memory and can serve queries on these segment files. Finally, the Broker would aggregate all of the partial results and return one result set to the client.

For a given query each segment file is handled by a single thread on a single historical. Due to this Druid guidelines recommend having segment files of a few hundred MBs for best query performance, trying to balance concurrency with the overhead associated with additional segment files.
Segment files are immutable and do not support quick update operations. As a result, Druid ingestion supports either overwriting a time-chunk with new segment files or adding segment files to an existing time-chunk.
This fact is integral to the problem we will be discussing here — Druid doesn’t support a way to quickly replace some of the data in a time-chunk with a new set of data. You can either replace all or none.
Data in Singular’s pipeline
Our analytics pipeline runs tens of thousands of daily jobs, each pulling data from a single data source for a single Singular customer and date range. Those jobs then normalize and enrich the data and eventually schedule it for database data ingestion.
The pipeline is effectively partitioned into 3 dimensions -
- Customer — the Singular account to which the data belongs.
- Date — the date associated with the data points.
- Source — the source from which the data is pulled.
It’s important for us to have the most updated and accurate data possible. As a result our pipeline often reprocesses existing partitions. In fact, this is what we do most of the time. Reasons are either because we’ve learned something new about the data and want to re-enrich it, or because there have been data changes in the source.
For example, every day we pull data from the latest 30 days for all sources to make sure that we keep up with delayed metrics and retroactive updates. That means that each pipeline partition is processed and updated at least 30 times.
Data in Singular’s Druid
We use Customer and Date to partition the data in our Druid, you may have noticed that unlike our pipeline partitioning we don’t utilize the Source as part of the partitioning scheme.
Date-based partitioning comes naturally to Druid. We use telescopic segmentation of the data so that the most recent data is partitioned by day, older data by week, and older still by month.
We achieve Customer partitioning by creating a different table per customer. This has many benefits other than data modelings, such as multi-tenancy segregation and easier maintenance.
While we could have created a table for each Customer x Source we chose not to. Our reasoning is that it would end up complicating our data model, increase query costs, and most importantly would cause an explosion of very small tables and segments which goes against Druid’s best practices and would significantly increase the data footprint and query times.
So we are left with a disparity between our pipeline partitioning scheme and our Druid’s partitioning scheme. Remember I mentioned Druid doesn’t support replacing data in granularity higher than time-chunks? this is where it comes into play. Our pipeline tries to update data for Customer x Date x Source, but we can’t just do that.
How we used to load data into Druid
Originally we considered two solutions to solve the partition disparity issue
- Reingest and re-index the whole Druid partition including data from sources that weren’t updated.
- Calculate a diff between the source’s old data to its new data and load it into Druid without replacing existing data.
While the second option is more efficient it packs a lot of risk and complications in it. To implement it we’ll need a reliable and efficient diffing mechanism alongside locks that delay some data updates to avoid race conditions and failures (and even then there are possible risks that we might run into).
Data correctness is very important to us and so we chose the first option — always reingest the whole Druid partition. It’s a simple and atomic operation that is idempotent and mitigates most of the risks. And it worked wonderfully for 3 years until the cracks started to show.
This method has one big caveat which became problematic after we’ve grown significantly — for every update we make, we need to re-ingest a large amount of existing data. For example, if we had a customer with 50 sources and only one day of one of those sources’ data was updated we’d need to re-ingest all 50. If the updated data is segmented monthly we’d need to re-ingest a month’s worth of data for the 50 sources just to update one day of one of the sources.
We could reduce that cost by batching our updates and only pushing new data into the database in a slower cadence. This kind of solution was a no-go for us as we wanted our customers to always have the most up-to-date data without needing to wait.
Additionally, we reached a point where some very small updates required huge ingestion jobs that would take hours and so would have a low updating cadence even without batching. When this started happening we realized we needed a better solution.
How we load data to Druid now
To recap — we wanted to be able to update partial data in a Druid segment without relying on a diffing mechanism and without costly ingestion tasks. Our problem was that Druid doesn’t really support this use case.
The solution to our problems came from a pretty simple realization — we can do more work in query time to allow us more flexibility during ingestion. Specifically, we could version the data for each pipeline partition and append it to the existing data, then during query, we could filter only for the most recent version for each pipeline partition (Customer x Date x Source).
This solution sounds simple but has some hurdles that must be addressed.
Small segments
The first of these problems is that this method introduces a lot of small segment files into the mix. It happens because each ingestion job creates its own segment files, so many small ingestion jobs lead to many small segment files. This goes directly against Druid’s best practices for quick queries.
Furthermore, many of those segment files would be filtered out and not actively used to drive results, but they will still be scanned to some degree requiring a historical thread for each. While it might be possible to prune most of those at the broker level using single_dim partitioning it’s still far from ideal. Another complication is that those small segments will never be used but will still be loaded into memory on the historicals and will waste a lot of memory resources.
We solved this problem by periodically cleaning unused segment files, we do it by utilizing segment metadata queries. Metadata queries allow learning information about the specific segment files such as cardinality and min/max of columns. We use these queries to get min/max values for the versions, sources, and dates in each segment file. We then compare these to the latest values for each partition. If we find a segment file that’s not needed anymore (has only old data) we delete it.
While this solves the problem of unused stale segments, we are still left with plenty of small used segments. Those, over time, could lead to reduced query performance. One possible solution is to run compaction, but then we still maintain a lot of unneeded data as we can’t filter out old versions during compaction unless we’ve deleted their segment before.
Another option is to reindex once in a while, but that requires time-chunk locking on the table (which will delay further appends during the indexing) or using an experimental segment lock which doesn’t work with Hadoop ingestion which we use for big tasks.
We turned to a third option which is to maintain 2 tables, a primary table, and an append table. The append table will host the small incremental segment files and is generally meant to hold data for a short time period. The primary table will host data for the long term, it will have only one version of each partition and will have data ingested into it once in a while.
We ended up with the following process:
- New incremental updates go into an append table using
appendToExisting - As more new updates come in we automatically delete unused segment files
- Once every 24 hours we reingest all updates and their respective Druid partitions into the primary table
- Existing data in the append table was rendered unneeded and will be automatically deleted
Filter complexity
We expect to have multiple versions of the same pipeline partition loaded at the same time so we need to make sure we filter on the latest versions. Such a filter would look something like this:
(source='Facebook' AND date='2021-01-01' AND version='ver1') OR (source='Facebook' AND date='2021-01-02' AND version='ver2') OR (source='Adwords' AND date='2021-01-01' AND version='ver3') OR ...
When considering that a query might run on thousands or tens of thousands of partitions this filter complexity can become a true problem and might hinder performance or just outright fail queries due to being too big.
The key to reducing filter complexity lies in the same primary table we introduced earlier as it provides us with a table that has the majority of the historic data and contains up to a single version of data for each pipeline partition, which means it doesn’t need explicit filtering for partition versions.
The best way to explain that would be to use an example. Let’s assume much like the previous example that we have only data for Adwords and Facebook for 2021–01–01/02 in our append tables, the filter would look like this:
(
table_type='Append' AND (
(source='Facebook' AND date='2021-01-01' AND version='ver1') OR
(source='Facebook' AND date='2021-01-02' AND version='ver2') OR
(source='Adwords' AND date='2021-01-01' AND version='ver3')
)
) OR
(
table_type='Primary' AND (
date not in ('2021-01-01', '2021-01-02') OR
(date='2021-01-01' and source not in ('Facebook', 'Adword')) OR
(date='2021-01-02' and source not in ('Facebook',))
)
)You may have noticed that we filter on table_type here is a constant column we add during ingestion to each table based on its type so we could easily filter all primary/append data.
This type of filter scales well as its complexity is mostly dependent on fresh data in the append and doesn’t change if significantly more data from the primary is queried.
We’ve tested many ways to construct the filter, trying to take advantage of fast paths during filtration (for example when an AND expression has only false on the left side), the final filter looks a bit different but we haven’t noticed major performance differences between variations of the filter.
Version state
To build a filter like mentioned before we need information about the latest versions of loaded data for each source and date per customer. We realized we can easily query that from Druid by running a group-by query on source, date, and version on the appropriate append table. We called this query a strategy query as its result allows us to build the query strategy.
The strategy query is a neat concept because it means that we don’t need to maintain a separate DB with a versioning state, and we always like to reduce statefulness in our systems. But it has a clear downside — each query to the DB requires another query beforehand. To circumvent this problem we cache the strategy query results and run them only when we have a cache miss or when new data is loaded to the DB. So we still update the cache when we expect changes but if we run into problematic edge cases we’d still serve correct results (if slightly outdated) and will be eventually consistent.
Another neat benefit is that our developers can query the database from dev environments without needing to access the version state in production.
There’s one caveat to this approach which is dealing with deletion of an existing version without replacing it with a new one (deleting data for Customer x Date x Source). Currently, we deal with it by fast-tracking ingestion into the primary table without the removed data. Once the primary ingestion is done the existing data from the older data from the append table will not be used anymore. In the future, we’d like to instead push a tombstone line with a newer version to the append table, which would be quicker and more efficient but since deletions such as these are not common it wasn’t a priority for us.
Query performance
We were worried about query performance and have benchmarked thoroughly before deployment and continued with a well-monitored gradual deployment. We haven’t seen any statistically significant performance degradation in the system for queries.
Results
Following the project’s deployment, we have seen a huge improvement in the time it takes for data to be available to our customers.
For example, here we see the time when we went with this feature out of beta. This graph shows the time it took on average for our highest priority data (fresh data from the last day) to load into the DB across customers. We’ve decreased it from averaging 45 minutes (with peaks of 2 hours) to averaging 2 minutes:
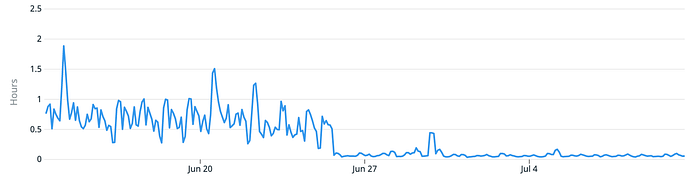
Funnily enough, most of these 2 minutes are actually spent waiting for Druid’s Overlord to recognize that a new segment file exists and assign it to a Historical.
We can also take a look at longer periods of time and include all recurring jobs in Singular and see a huge improvement -
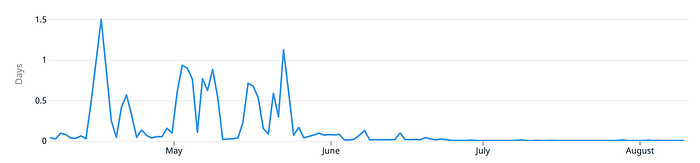
We start seeing a major improvement during late May / early June — that’s when we have onboarded our heaviest customers into this new feature.
Closing thoughts
I’d like to go a bit meta before going back to tech. I believe the strongest lesson here is not how to upsert data into Druid but rather one of system lifecycle and culture. The solution described here wasn’t the correct thing for Singular of 2 years ago and before that Druid wasn’t the correct solution for Singular, a MySQL instance was enough. It’s important to not over-build, make sure you have a solution that would work for the foreseeable future but not more than. At the same breath, make sure you spend time on improving your infra and doing it right. This project wasn’t done in 2 sprints, it took more than a quarter of hard work. The result is a high-quality solution that works but is also tested, stable, and easily maintainable. There’s a lot that wasn’t said in this blog post about the benchmarking, fail-safes, and edge cases that we built or dealt with while working on this project, it’s easy to forget about those but the majority of the work is found there.
As for the tech side of things, we have learned a lot and have a lot to learn still. While we love Druid this wasn’t the last issue we’d like to tackle. For example, we use real-time ingestion for some of our data, due to how Druid real-time ingestion works we are forced to mix different customers' data for this type of ingestion. That in turn creates query performance issues where even small customers are very affected by the loads that bigger customers create on the system. At the first stage, we plan to tackle it with heavy data compaction tasks, but I’d really love to see some improvements in Druid to allow better multi-tenancy in realtime ingestion, perhaps by enabling single dimension partitioning for realtime.
Something else that I’d love to see is better support for virtual columns based on multiple dimensions. While Druid does support this feature, it's far from optimized and results in abysmal performance from our testing. To solve this problem we’ve developed a java based plugin to Druid that takes a single field with many fields concatenated into it and can run configurable logic on top of that. This solution works well, but requires ingesting a very high cardinality column and still has some performance limitations.
This post was written by Yonatan Komornik. If you have any questions or feedback, please contact Yonatan at yonatan@singular.net.
